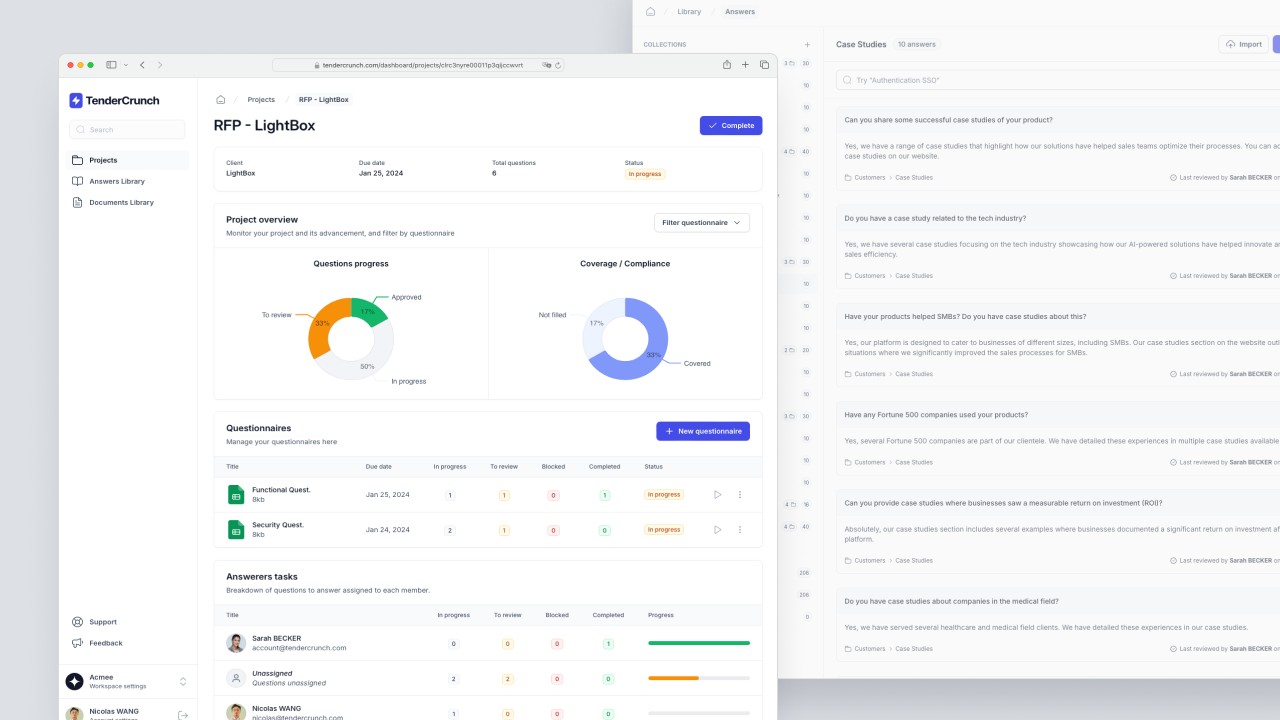
What is TenderCrunch
TenderCrunch is an AI-driven web application that accelerates the process of responding to RFPs and other data-intensive questionnaires. It simplifies collaboration and automates responses, significantly reducing the time and effort involved in proposal management. By centralizing information and utilizing AI to quickly provide accurate answers, companies can efficiently complete more proposals with a higher chance of success.
How we built TenderCrunch
The primary objective was to develop a sophisticated system known as Retrieval Augmented Generation that automates the process of drafting responses for new Requests for Proposals (RFPs) by leveraging a custom-built knowledge base. This knowledge base consists of content from previously answered RFPs and various internal documents provided by the user.
The system works in two ways:
Firstly, for the information retrieval part, we used a Vector Database. This database converts the text from previous RFPs and documents into numerical vectors—high-dimensional representations that encode the semantic meaning of the text using machine learning algorithms. By transforming text into vectors, the system can perform semantic searches. This means when a new RFP is uploaded, the system can scan through these vectors to identify and retrieve the portions of text from the knowledge base that are semantically closest to the questions within the new RFP.
The second step involves the generation of responses using a Large Language Model (LLM). The LLM processes the retrieved information, understanding the context and the specific demands of the RFP questions. It then writes an appropriate draft response. The quality of the LLM's output relies heavily on both the relevance of the retrieved data and its capacity for natural language understanding and generation.
Integrating the Vector Database with the LLM presented a significant engineering challenge. We had to make sure that the embeddings generated for the search were optimally tuned to retrieve the most useful content, and that the LLM was configured to understand the structure and requirements of various RFPs to generate high-quality responses.
By resolving these challenges, we managed to create a robust system capable of reducing the time and effort required to respond to RFPs while maintaining a high standard of quality and accuracy in the generated responses.